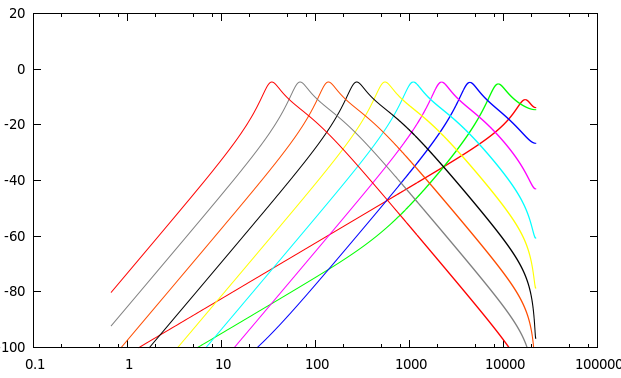
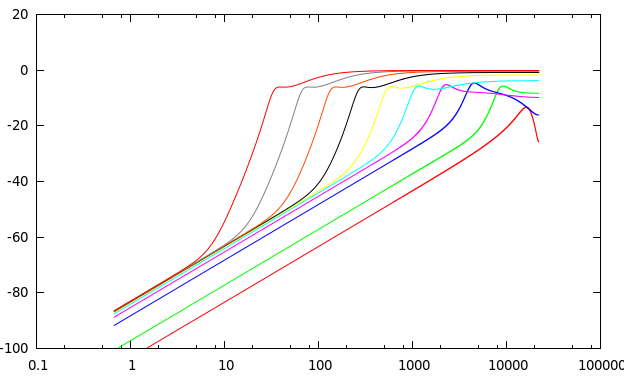
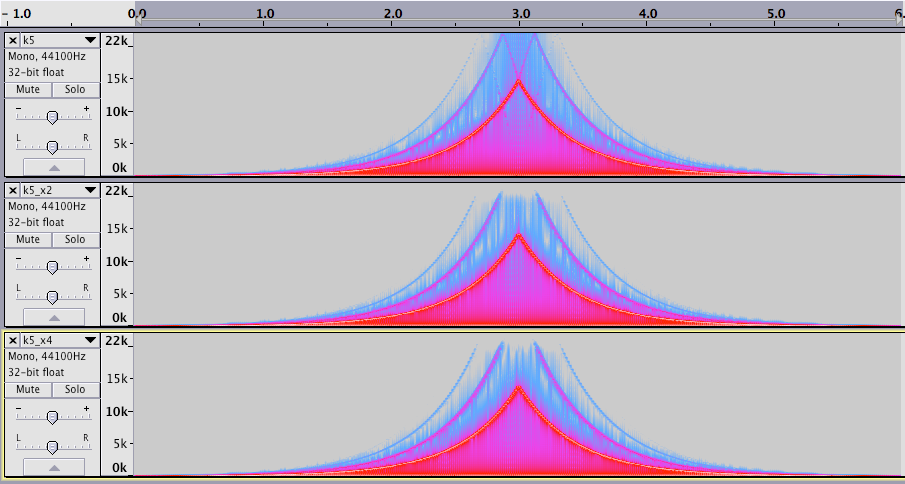
The spiking is expected behavior: the previous sound under-estimates the attenuation required for the next sample. Proper oversampling helps in two ways: the up-sampling filter will make the input smoother, and most of the spikes will be at higher frequencies, so the down-sampling will filter them out.raphx wrote: But when you really push the input gain, the output waveform gets more "spiky." This is true no matter how high you push the oversampling.
If you aren't getting any improvement with oversampling, then I suspect you are taking some unsafe short-cuts (like not using proper filtering both ways). There will certainly be Gibbs spikes from the down-sampling, but that's different and expected from any method.
That said, you need pretty silly over-sampling for high-gain situations. If that's what you want to do, then this is not a good approach. Note that the tanh(x)/x approximation that I proposed doesn't work for high-gain either, so you would also need to improve that one.
I actually recently found out that some pre-historic (pre-SPICE) circuit simulator apparently used (with iteration) a scheme very similar to what I proposed.Z1202 wrote:My general feeling (no proof) is that mystran's approach should work better for not-so-extreme settings, whereas the cheapest approach should deliver better results at the extremes.
But.. yes, I designed it to be "the most simple thing that could work" for the case where you can get reasonable results without iteration. For high-gain situations you want iteration, and then it makes sense to switch to Newton instead, which only costs marginally more per iteration, generally converges much faster, and kinda benefits more from oversampling too.
As for simply altering the solution, yeah that's cheap, but IIRC you can run into problems if you don't clip the state-variables, and clipping the state-variable isn't quite the right thing (so you're not really solving the right system).
It is not obvious to me how one would do this while still solving the same system. Do you mean like solving the currents, estimating what the resulting voltages would be, applying the non-linearities and then estimating the currents again from those (and integrating those) or what?Z1202 wrote: There's also the "cheapest" approach, which simply applies nonlinearities on top of the zero-delay feedback solution (without attempting to use any "history" data).
Care to provide some links if this was discussed somewhere?
I know you can also just clip the state-variables or some such similar thing, but that isn't really the same filter anymore then..