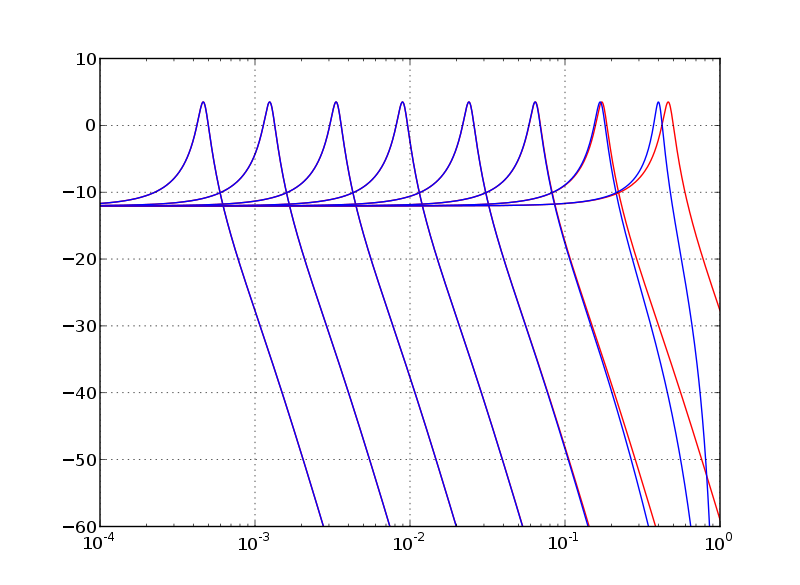
Did you do the cutoff prewarping? I mean the BLT and analog responses should exactly match at the cutoff frequency. Your graph somehow looks different.karrikuh wrote:Frequency response of TPT filter with BLT integrators should perfectly match analog prototype except frequency warping, like this (no oversampling here, red=analog, blue=BLT-TPT):

A matrix approach to the Moog ladder filter
-
- KVRAF
- 1607 posts since 12 Apr, 2002
-
- KVRAF
- 1607 posts since 12 Apr, 2002
TPT is equivalent to state-space discretization (you might need to do a little trick to incorporate TDF2 BLT integration into the state-space form, but nothing esoteric).karrikuh wrote:That said, depending how sofisticated your exp(AT) approximation is, yes, your state space implementation will give better results than bilinear TPT (which, I think, is equivalent to bilinear state space discretization, because they are using the same state variables)
As for matrix-exponential approach giving better results than BLT, I guess we are still waiting for correct ampl/phase response comparisons. I really wonder, how strong the effect of naive sampling is going to be. I would also keep in mind that at 88kHz SR (which is not that uncommon for analog modeling) the frequency warping is not as noticeable as at 44.
-
- KVRAF
- 1607 posts since 12 Apr, 2002
The amplitude response is really nice. I'm still wondering about the phase effects, though (the phase must be more different, since you can get only 0 or 180 at Nyquistraphx wrote:I redid the TPT plots based on mystran's implementation in the "cheap non-linear zero delay filters" thread, and they're looking much more reasonable. Will Pirke should revise or withdraw his application note, as it's seriously misleading (although of course I take responsibility for jumping the gun - I should have realized that the response was identical to the analog prototype save for bilinear frequency warping).
http://levien.com/ladder/graphs2.pdf
Edit: although to the left of 11kHz the BLT plots are not that far off the analog response, which corresponds to the audible range at 88kHz SR
-
- KVRian
- 626 posts since 29 Jul, 2003 from Paris - France
I didn't tried it myself, but from the 3 classic discretization schemes shown above, it's clear that they're Taylor / Pade approximations of the matrix exponential. One should be able to substitute any higher-order approximations of exp using Taylor series / Padé rational functions straight from the books.mdsp wrote: Forward Euler: e^AT ~ I+AT
Backward Euler: e^AT ~ (I-AT)^-1
Trapezoidal / bilinear: e^AT ~ (I+AT/2)(I-AT/2)^-1
http://mathworld.wolfram.com/PadeApproximant.html
Higher-order explicit: e^AT ~ I + sum(n=1:N, AT^n / n!)
Higher-order implicit: e^AT ~ (I+sum(n=1:N, (-AT)^n / n!))^-1
semi-implicit 2/2: e^AT ~ (12*I+6*AT+(AT)^2)(12*I-6*AT+(AT)^2)^-1
semi-implicit 3/3: e^AT ~ (120*I+60*AT+12*(AT)^2+(AT)^3)(120*I-60*AT+12*(AT)^2-(AT)^3)^-1
...etc
What's not intuitive though, are the implications on stability and frequency axis distortion resulting from the non-linear mapping from the Laplace to the Z domains.
I'd be interrested to know if there exists a reference with detailed analysis of higher-order numerical schemes and their physical interpretation.
For now all I've been tought is that explicit schemes are often unstable when diffenrential equations are stiff (higher-orders and oversampling should increase the domain of stability), implicit schemes are stables but overdamped and that only the bilinear transform preserves stability and filter order at the price of frequency axis warping.
-
- KVRAF
- 3388 posts since 29 May, 2001 from New York, NY
Interesting approach. Can't the iterative matrix exponentiation be skipped entirely, using this: http://goo.gl/Sb1nc ?
-
- KVRAF
- 3388 posts since 29 May, 2001 from New York, NY
Interesting approach. Can't the iterative matrix exponentiation be skipped entirely, using this: http://goo.gl/Sb1nc ?
-
- KVRian
- 626 posts since 29 Jul, 2003 from Paris - France
you can even do that:
http://wolfr.am/17F9p6N
I've used the Analog state transition matrix with a = 2*pi*f/sr
The analytical solution exists in this case, but that's not the kind of stuff you want to compute at audio-rate...
http://wolfr.am/17F9p6N
I've used the Analog state transition matrix with a = 2*pi*f/sr
The analytical solution exists in this case, but that's not the kind of stuff you want to compute at audio-rate...
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
mdsp: Interesting. I see a lot of repeated stuff in there, and suspect it's possible to simplify. I started by replacing r with r^4. This might actually fly, especially because I have obsessively fast implementations of exp and sin already.
http://wolfr.am/1cqQyce
I'll see how much more I can simplify it.
Z1202: phase plots coming up in a bit.
http://wolfr.am/1cqQyce
I'll see how much more I can simplify it.
Z1202: phase plots coming up in a bit.
-
- KVRian
- 626 posts since 29 Jul, 2003 from Paris - France
yes there's a lot of repeated terms, I'd be curious to know what is the minimum number of operations. And BTW I've just spotted a complex number in there... either there's no real analytical solution or Mathematica's hypothesis are too large.raphx wrote:mdsp: Interesting. I see a lot of repeated stuff in there, and suspect it's possible to simplify. I started by replacing r with r^4. This might actually fly, especially because I have obsessively fast implementations of exp and sin already.
http://wolfr.am/1cqQyce
I'll see how much more I can simplify it.
Z1202: phase plots coming up in a bit.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
As promised, the phase plots. I don't have an analytic analog solution for comparison yet, but I think it's possible to interpret these graphs anyway.
http://levien.com/ladder/graphs_ph.pdf
Here I think the TPT plots are better - phase goes to -2pi at Nyquist, which is the limit in the analog case. It's also suggesting (as I had already begun to intuit) that the matrix technique is going to work a lot better for lowpass than highpass, at least without doing the extra FIR filter.
mdsp: there's a huge amount of structure in there. Note (for some reason I hadn't spotted it before, even though I was looking at a bunch of matrices in my numerical solver) the diagonal stripes of repeated values.
It's also not too surprising that the left column is more complicated than the body of the transition matrix - the former is basically integrated across a square pulse that lasts exactly one sample period, while the latter probably just captures the resonances of the filter quite directly as eigenvalues. I wouldn't be surprised if it was possible to do something "good enough" with that, while using an analytical solution for the transition.
http://levien.com/ladder/graphs_ph.pdf
Here I think the TPT plots are better - phase goes to -2pi at Nyquist, which is the limit in the analog case. It's also suggesting (as I had already begun to intuit) that the matrix technique is going to work a lot better for lowpass than highpass, at least without doing the extra FIR filter.
mdsp: there's a huge amount of structure in there. Note (for some reason I hadn't spotted it before, even though I was looking at a bunch of matrices in my numerical solver) the diagonal stripes of repeated values.
It's also not too surprising that the left column is more complicated than the body of the transition matrix - the former is basically integrated across a square pulse that lasts exactly one sample period, while the latter probably just captures the resonances of the filter quite directly as eigenvalues. I wouldn't be surprised if it was possible to do something "good enough" with that, while using an analytical solution for the transition.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
And here's the analytical solution, in what I think is a minimum number of operations. I think this is in the same ballpark as TPT now if you're updating it at audio rate, and much much faster if your control rate is lower.
Don't ask me exactly how I did this. It was a combination of Wolfram Alpha, factoring polynomials like crazy with pen and paper, and trying things out in Python to make sure the simplified formulas actually computed the right answer.
Note that b_i is just (1 - sum_j a_{j,5-i}) / (1 + k), for reasons I don't completely understand, but it's so simple a relation there must be an intuitive explanation. This is what took me the most time, as the WA formulas were way more complicated than for the transition matrix core. I just kept simplifying and simplifying until I saw that all the terms were the same. Note that even if you still want to compute the exponential numerically (as in the checked-in code), this insight gives you an additional speedup: you can compute the core with pure 4x4 matrix operations instead of fake 5x5 with the constant top row, and fill in the B vector after that's done.
Don't ask me exactly how I did this. It was a combination of Wolfram Alpha, factoring polynomials like crazy with pen and paper, and trying things out in Python to make sure the simplified formulas actually computed the right answer.
Note that b_i is just (1 - sum_j a_{j,5-i}) / (1 + k), for reasons I don't completely understand, but it's so simple a relation there must be an intuitive explanation. This is what took me the most time, as the WA formulas were way more complicated than for the transition matrix core. I just kept simplifying and simplifying until I saw that all the terms were the same. Note that even if you still want to compute the exponential numerically (as in the checked-in code), this insight gives you an additional speedup: you can compute the core with pure 4x4 matrix operations instead of fake 5x5 with the constant top row, and fill in the B vector after that's done.
Code: Select all
q4 = k * 0.25
q = q4 ** .25
qr = 1 / q
q2r = qr * qr # 1/sqrt(q4)
q3r = q2r * qr
t1 = exp(-a * (1 + q))
t2 = exp(2 * a * q)
t3 = cos(a * q)
t2c = t2 * t3
t2cp = t1 * (t2c + t3)
t2cm = t1 * (t2c - t3)
t4 = sin(a * q)
t2s = t2 * t4
t2sp = t1 * (t2s + t4)
t2sm = t1 * (t2s - t4)
t7 = t2cm + t2sp
t9 = t2cm - t2sp
a11 = .5 * t2cp
a21 = .25 * t7 * qr
a31 = .25 * t2sm * q2r
a41 = -.125 * t9 * q3r
a12 = -k * a41
a22 = a11
a32 = a21
a42 = a31
a13 = -k * a42
a23 = a12
a33 = a22
a43 = a32
a14 = -k * a43
a24 = a13
a34 = a23
a44 = a33
recip = 1 / (k + 1.0)
t10 = 1 - a44
t11 = t10 - a34 - a24
b1 = (t11 - a14) * recip
b2 = (t11 - a43) * recip
t12 = t10 - a42 - a32
b3 = (t12 - a12) * recip
b4 = (t12 - a41) * recip
return np.matrix([[1, 0, 0, 0, 0],
[b1, a11, a12, a13, a14],
[b2, a21, a22, a23, a24],
[b3, a31, a32, a33, a34],
[b4, a41, a42, a43, a44]])
Last edited by raphx on Fri Jun 28, 2013 5:17 pm, edited 1 time in total.
-

- KVRAF
- 8491 posts since 12 Feb, 2006 from Helsinki, Finland
Your specific state-space is so regular and sparse that an LU factorization with a bit of hand-optimization is something like 2 division and 4 multiply-adds, and you need 3 mul-adds for the forward substitution and maybe something like 7 for the backward substitution (maybe less, can't think right now).
I don't see how your analytical solution is comparable.
I'm not trying to say it's not a nice technique, but trapezoidal for simple sparse systems is really quite fast.
edit: I'd also like to add that, yes, it does get more expensive when the system is such that you can't take as many short-cuts, or when the thing isn't quite that sparse.. but comparing apples to apples, it's really not that expensive.
I don't see how your analytical solution is comparable.
I'm not trying to say it's not a nice technique, but trapezoidal for simple sparse systems is really quite fast.
edit: I'd also like to add that, yes, it does get more expensive when the system is such that you can't take as many short-cuts, or when the thing isn't quite that sparse.. but comparing apples to apples, it's really not that expensive.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
mystran: I'm also counting the cost of the tan for frequency warping. I totally agree that solving the TPT-BLT system is cheap. I should probably be clearer what I'm claiming:
1. The cost of solving the expm for the ladder filter is not too bad, whether numerical or analytical. I expect it to be slower than BLT, but not by a huge factor.
2. Updating the state vector through multiplication with the transition matrix is going to be faster than cascading 1-pole filters, because the matrix approach enables maximum parallelism, while the cascaded one-poles have serial data dependencies. This is independent of how the transition matrix is computed.
The performance question is fairly complex. It depends on whether you're updating parameters at audio rate, whether you're doing SIMD or scalar computation, and, if SIMD, whether you're trying to exploit parallelism for a single datapath or whether you're doing four independent filters so exploiting the parallelism of polyphony.
In the particular case (which matches my synth) where you're updating at control rate, using SIMD, and computing a single stream at a time, I expect the performance of the matrix approach to be impressive. I will probably have real performance data soon, so am not making any bold claims until then, just speculating about what I expect it to show.
The other factor affecting performance is the degree of oversampling. In the linear case I maintain that there's no need to do any oversampling if your response is accurate enough, so would claim that matrix exponential at 44.1kHz has comparable accuracy to TPT-BLT at 88.2, at potentially much higher performance. However, the linear case isn't all that interesting - the next thing I really want to look into is how nonlinearity changes things.
1. The cost of solving the expm for the ladder filter is not too bad, whether numerical or analytical. I expect it to be slower than BLT, but not by a huge factor.
2. Updating the state vector through multiplication with the transition matrix is going to be faster than cascading 1-pole filters, because the matrix approach enables maximum parallelism, while the cascaded one-poles have serial data dependencies. This is independent of how the transition matrix is computed.
The performance question is fairly complex. It depends on whether you're updating parameters at audio rate, whether you're doing SIMD or scalar computation, and, if SIMD, whether you're trying to exploit parallelism for a single datapath or whether you're doing four independent filters so exploiting the parallelism of polyphony.
In the particular case (which matches my synth) where you're updating at control rate, using SIMD, and computing a single stream at a time, I expect the performance of the matrix approach to be impressive. I will probably have real performance data soon, so am not making any bold claims until then, just speculating about what I expect it to show.
The other factor affecting performance is the degree of oversampling. In the linear case I maintain that there's no need to do any oversampling if your response is accurate enough, so would claim that matrix exponential at 44.1kHz has comparable accuracy to TPT-BLT at 88.2, at potentially much higher performance. However, the linear case isn't all that interesting - the next thing I really want to look into is how nonlinearity changes things.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
I've done a little bit more exploring of nonlinearities, including checking in a non-oversampled implementation to my synth's source tree. I think it sounds pretty good.
Here are the tentative conclusions I've come to (and I'll probably put together some data to back these up):
1. The mystran implementation of "cheap non-linear zero-delay filters" is very interesting. In my tests, it's not computing exactly the same differential equations as Huovilainen. For inputs around -1..1, it's very very close, however. But when you really push the input gain, the output waveform gets more "spiky." This is true no matter how high you push the oversampling.
In the other direction, it's a bit better at rejecting aliasing than anything that applies a nonlinear function directly to the input, I think mostly because the input is gently lowpass filtered before hitting the nonlinearity. But this becomes less important as you oversample.
2. Applying the nonlinearities as I sketched in the paper draft works well. It sounds good to my ears without oversampling, and then seems to converge rapidly as the oversampling goes up. I think at 2x oversampling it's quite usable, and at 4x, pretty much all artifacts are gone.
Incidentally, the best way to evoke aliasing is to input a swept sine at high gain.
3. I'm finding that I really do prefer the full set of differential equations, rather than just saturating one of the stages. Among other things, the latter has a tendency to become a square wave, losing even harmonics, as input gain goes up, and that doesn't sound "analog warm" to me.
4. I personally can't hear the difference between tanh as a sigmoid and 1/(1+x*x). The latter also has the very nice property that you can scale the amount of distortion all the way to zero without worrying about numerical problems. I consider the inv sqrt to be an entirely valid approximation to tanh.
The amount of aliasing is slightly higher than tanh, though, when you look at spectrum plots. I think tanh has near magical properties of having its harmonics drop off quickly, which makes it especially useful for avoiding aliasing. But chips these days have special instructions for computing 1/sqrt, and I think it's worth taking advantage of that. If you really care about aliasing, use the fastest possible implementation and oversample a bit more.
5. I've started in on SIMD implementation, and am increasingly confident that performance will be impressive. I'm seeing something like 75 cycles per sample in a cycle counter on Cortex A8. It's not fully working code yet, and I haven't carefully measured it against other alternatives, but my strong guess is that this is an order of magnitude faster than previous implementations.
I'm making these speed claims for the case where parameters aren't updated all that frequently (my synth does it every 64 samples). If you really need to modulate at audio rate, TPT is probably better.
Thought you guys might be interested in the update.
Here are the tentative conclusions I've come to (and I'll probably put together some data to back these up):
1. The mystran implementation of "cheap non-linear zero-delay filters" is very interesting. In my tests, it's not computing exactly the same differential equations as Huovilainen. For inputs around -1..1, it's very very close, however. But when you really push the input gain, the output waveform gets more "spiky." This is true no matter how high you push the oversampling.
In the other direction, it's a bit better at rejecting aliasing than anything that applies a nonlinear function directly to the input, I think mostly because the input is gently lowpass filtered before hitting the nonlinearity. But this becomes less important as you oversample.
2. Applying the nonlinearities as I sketched in the paper draft works well. It sounds good to my ears without oversampling, and then seems to converge rapidly as the oversampling goes up. I think at 2x oversampling it's quite usable, and at 4x, pretty much all artifacts are gone.
Incidentally, the best way to evoke aliasing is to input a swept sine at high gain.
3. I'm finding that I really do prefer the full set of differential equations, rather than just saturating one of the stages. Among other things, the latter has a tendency to become a square wave, losing even harmonics, as input gain goes up, and that doesn't sound "analog warm" to me.
4. I personally can't hear the difference between tanh as a sigmoid and 1/(1+x*x). The latter also has the very nice property that you can scale the amount of distortion all the way to zero without worrying about numerical problems. I consider the inv sqrt to be an entirely valid approximation to tanh.
The amount of aliasing is slightly higher than tanh, though, when you look at spectrum plots. I think tanh has near magical properties of having its harmonics drop off quickly, which makes it especially useful for avoiding aliasing. But chips these days have special instructions for computing 1/sqrt, and I think it's worth taking advantage of that. If you really care about aliasing, use the fastest possible implementation and oversample a bit more.
5. I've started in on SIMD implementation, and am increasingly confident that performance will be impressive. I'm seeing something like 75 cycles per sample in a cycle counter on Cortex A8. It's not fully working code yet, and I haven't carefully measured it against other alternatives, but my strong guess is that this is an order of magnitude faster than previous implementations.
I'm making these speed claims for the case where parameters aren't updated all that frequently (my synth does it every 64 samples). If you really need to modulate at audio rate, TPT is probably better.
Thought you guys might be interested in the update.
-
- KVRAF
- 1607 posts since 12 Apr, 2002
There's also the "cheapest" approach, which simply applies nonlinearities on top of the zero-delay feedback solution (without attempting to use any "history" data). IIRC, mystran's approach is somewhere in the middle between this "cheapest" approach and a single Newton-Raphson iteration. The cheapest approach might be better in terms of "spikiness", although I am not sure. My general feeling (no proof) is that mystran's approach should work better for not-so-extreme settings, whereas the cheapest approach should deliver better results at the extremes.raphx wrote:1. The mystran implementation of "cheap non-linear zero-delay filters" is very interesting. In my tests, it's not computing exactly the same differential equations as Huovilainen. For inputs around -1..1, it's very very close, however. But when you really push the input gain, the output waveform gets more "spiky." This is true no matter how high you push the oversampling.
It's strange that the spikiness is independent of the oversampling, though.