Back to the ladder filter (beginner SIMD is probably a good topic for another thread, although to be fair SIMD was a huge part of the motivation for this in the first place).
I finally coded up a reasonably efficient C++ implementation of the linear version and integrated it into my synth. I personally feel that the code is beautiful and still reasonably simple. A fair amount of the new code is generic matrix operations, which as I keep saying will get a lot faster in SIMD. I used a slightly more sophisticated approximation to the matrix exponential ( a few rounds of Taylor series, followed by scaling and squaring), largely so that it would be more robust in all 32-bit float arithmetic.
https://code.google.com/p/music-synthes ... 1f415bb91d
In listening tests, I like this filter a lot. Running it for real validates my expectation that it smoothly handles changes of parameters. This isn't surprising because the state corresponds exactly to the voltages at the various stages of the Moog ladder, so you'd expect parameter changes to behave the same as well.
Next stop, nonlinearity. I want to implement 2x oversampling first, though, and also implement fast sigmoids.

A matrix approach to the Moog ladder filter
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
-
- KVRian
- 626 posts since 29 Jul, 2003 from Paris - France
this wikipedia page gives a good summarize about the conversion from continuous to discrete state-space representations using the matrix exponential:
https://en.wikipedia.org/wiki/Discretization
Unfortunately, in the general case, the matrix exponential either doesn't have an analytical expression or is too complex to be used in real-time and we have to make approximations. The bottom of the page shows some of the common ones:
Forward Euler: e^AT ~ I+AT
Backward Euler: e^AT ~ (I-AT)^-1
Trapezoidal / bilinear: e^AT ~ (I+AT/2)(I-AT/2)^-1
combining A and B into a single matrix with successive exponentiation is a nice trick. It makes it both simple to implement and more accurate than Forward-Euler. And it doesn't involve matrix inverse or exponential. It seems like a good trade-off between cpu cost and accuracy.
https://en.wikipedia.org/wiki/Discretization
Unfortunately, in the general case, the matrix exponential either doesn't have an analytical expression or is too complex to be used in real-time and we have to make approximations. The bottom of the page shows some of the common ones:
Forward Euler: e^AT ~ I+AT
Backward Euler: e^AT ~ (I-AT)^-1
Trapezoidal / bilinear: e^AT ~ (I+AT/2)(I-AT/2)^-1
combining A and B into a single matrix with successive exponentiation is a nice trick. It makes it both simple to implement and more accurate than Forward-Euler. And it doesn't involve matrix inverse or exponential. It seems like a good trade-off between cpu cost and accuracy.
-

- KVRAF
- 8491 posts since 12 Feb, 2006 from Helsinki, Finland
Doesn't the exponentiation get a bit costly (especially for bigger systems) if you need audio-rate updates?
-
- KVRian
- 626 posts since 29 Jul, 2003 from Paris - France
Of course, this is the main problem. Matrix computations can dominate the CPU cost in the worst-case.mystran wrote:Doesn't the exponentiation get a bit costly (especially for bigger systems) if you need audio-rate updates?
However in the linear time-invariant case this approach shows that one can solve the continuouts differential equation system exactly (within numerical accuracy and input/output discretization hypothesis) instead of having to make compromises on the time or frequency response.
-
- KVRAF
- 1607 posts since 12 Apr, 2002
The solution is not exact, because of naive resampling involved. It's just a different set of compromises. For that reason, it would be nice to compare the amplitude (and phase) response graphs of analog, BLT and squared-matrix filters.mdsp wrote:Of course, this is the main problem. Matrix computations can dominate the CPU cost in the worst-case.mystran wrote:Doesn't the exponentiation get a bit costly (especially for bigger systems) if you need audio-rate updates?
However in the linear time-invariant case this approach shows that one can solve the continuouts differential equation system exactly (within numerical accuracy and input/output discretization hypothesis) instead of having to make compromises on the time or frequency response.
Regards,
{Z}
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
The Wikipedia article on Discretization is good in introducing matrix exponential as a solution, and the trick of combining A and B, but it's far from awesome about characterizing the error of the assumption of holding u constant (in the terminology of the article). That's the main thing I'm trying to understand (and tame). I believe it's a new observation that for the Moog ladder filter, this error is small enough to be insignificant.
Again, for the specific case of the Moog ladder filter, the cost of the exponential is teeny. I have it down to about 8 4x4 matrix multiplies in the worst case (cutoff frequency near Nyquist, resonance near self-oscillating) and will work out an error formula to use only the minimal number of iterations across the parameter space. My current C++ implementation updates the filter parameters every 64 samples in response to real-time control, and the whole thing runs at something like 3% of CPU on my phone (HTC One). And this is even without NEON, which I expect to provide massive speedup. I'll do more careful benchmarking when I do the NEON.
Again, for the specific case of the Moog ladder filter, the cost of the exponential is teeny. I have it down to about 8 4x4 matrix multiplies in the worst case (cutoff frequency near Nyquist, resonance near self-oscillating) and will work out an error formula to use only the minimal number of iterations across the parameter space. My current C++ implementation updates the filter parameters every 64 samples in response to real-time control, and the whole thing runs at something like 3% of CPU on my phone (HTC One). And this is even without NEON, which I expect to provide massive speedup. I'll do more careful benchmarking when I do the NEON.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
Z1202: You're quite right, that three-way comparison (matrix exponential, zero-delay BLT, and analog) is the most enlightening one to do. I actually didn't know about your zero-delay BLT approach when I started this work, so I was comparing against the old-school approach used by Huovilainen and others (cascaded 1-pole with a unit delay in the feedback path, with tweaks). I think it's fair to say it it's much better than that approach, so I think only worth comparing for historical reasons.
I'll see what I can do about making plots, although it will probably take a few days to get everything implemented in my test framework.
I have ideas about how to treat the high-pass case as well.
Would I be insane in thinking this work would be interesting enough for a conference, assuming I work out some more of the details? DAFx maybe?
I'll see what I can do about making plots, although it will probably take a few days to get everything implemented in my test framework.
I have ideas about how to treat the high-pass case as well.
Would I be insane in thinking this work would be interesting enough for a conference, assuming I work out some more of the details? DAFx maybe?
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
Okay, I was excited so I made the plots. I think you'll find that the results show that the matrix exponential implementation is dramatically better than TPT.
http://levien.com/ladder/graphs.pdf
I didn't plot phase, but can if needed. I expect the results to be similar to gain, as the sample-and-hold assumption itself introduces no phase distortion.
A few more details: the reference (shown in blue dashed lines) is the exponential filter for 39.0625 Hz, shifted right to match the expected cutoff frequency. Strictly speaking, for "analog" it would have been better to solve the transfer function for the ladder filter analytically, but numerically I expect it to be near perfect, and this is supported by the very close match for the TPT curve at that frequency. One artifact though is that the leftmost curve for exponential is artificially perfectly accurate.
My reference for the TPT code was Will Pirke's app note (http://www.willpirkle.com/Downloads/AN- ... ilters.pdf), which I found to be extremely helpful. My frequency plots for TPT very closely resemble figure 4.22 from that document, which inspires confidence in my measuring methodology. That's why I chose k = 3.176, which corresponds to his Q = 20, btw.
Results are similar for other k values, with one notable feature: the TPT filter does not stay stable for values over 3.437 or so. The matrix exponential filter stays rock solid all the way up to at least 3.99, as the stability properties are exactly the same as the analog prototype (modulo numerical error).
Based on these measurements, I'm going to make a bold claim: the matrix exponential approach is dramatically better than anything else out there, in all important respects. I'm eager to hear any arguments if people don't believe that.
http://levien.com/ladder/graphs.pdf
I didn't plot phase, but can if needed. I expect the results to be similar to gain, as the sample-and-hold assumption itself introduces no phase distortion.
A few more details: the reference (shown in blue dashed lines) is the exponential filter for 39.0625 Hz, shifted right to match the expected cutoff frequency. Strictly speaking, for "analog" it would have been better to solve the transfer function for the ladder filter analytically, but numerically I expect it to be near perfect, and this is supported by the very close match for the TPT curve at that frequency. One artifact though is that the leftmost curve for exponential is artificially perfectly accurate.
My reference for the TPT code was Will Pirke's app note (http://www.willpirkle.com/Downloads/AN- ... ilters.pdf), which I found to be extremely helpful. My frequency plots for TPT very closely resemble figure 4.22 from that document, which inspires confidence in my measuring methodology. That's why I chose k = 3.176, which corresponds to his Q = 20, btw.
Results are similar for other k values, with one notable feature: the TPT filter does not stay stable for values over 3.437 or so. The matrix exponential filter stays rock solid all the way up to at least 3.99, as the stability properties are exactly the same as the analog prototype (modulo numerical error).
Based on these measurements, I'm going to make a bold claim: the matrix exponential approach is dramatically better than anything else out there, in all important respects. I'm eager to hear any arguments if people don't believe that.
-

- KVRist
- 470 posts since 6 Apr, 2008
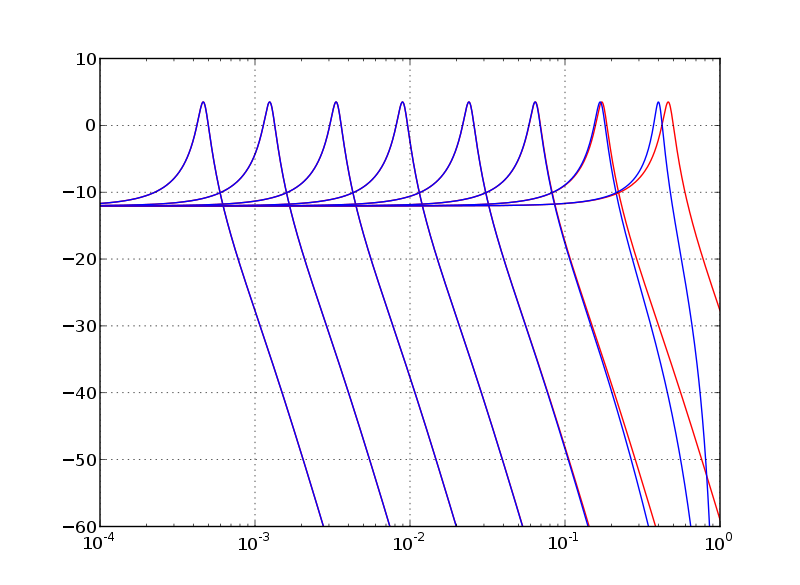
Looking at the results, it's obvious that TPT implementation you are comparing to is wrong (I did not bother to check the code in the PDF). Frequency response of TPT filter with BLT integrators should perfectly match analog prototype except frequency warping, like this (no oversampling here, red=analog, blue=BLT-TPT):raphx wrote:Okay, I was excited so I made the plots. I think you'll find that the results show that the matrix exponential implementation is dramatically better than TPT.
http://levien.com/ladder/graphs.pdf
I didn't plot phase, but can if needed. I expect the results to be similar to gain, as the sample-and-hold assumption itself introduces no phase distortion.
A few more details: the reference (shown in blue dashed lines) is the exponential filter for 39.0625 Hz, shifted right to match the expected cutoff frequency. Strictly speaking, for "analog" it would have been better to solve the transfer function for the ladder filter analytically, but numerically I expect it to be near perfect, and this is supported by the very close match for the TPT curve at that frequency. One artifact though is that the leftmost curve for exponential is artificially perfectly accurate.
My reference for the TPT code was Will Pirke's app note (http://www.willpirkle.com/Downloads/AN- ... ilters.pdf), which I found to be extremely helpful. My frequency plots for TPT very closely resemble figure 4.22 from that document, which inspires confidence in my measuring methodology. That's why I chose k = 3.176, which corresponds to his Q = 20, btw.
Results are similar for other k values, with one notable feature: the TPT filter does not stay stable for values over 3.437 or so. The matrix exponential filter stays rock solid all the way up to at least 3.99, as the stability properties are exactly the same as the analog prototype (modulo numerical error).
Based on these measurements, I'm going to make a bold claim: the matrix exponential approach is dramatically better than anything else out there, in all important respects. I'm eager to hear any arguments if people don't believe that.
A correct implementation also should behave stable for all k < 4.
That said, depending how sofisticated your exp(AT) approximation is, yes, your state space implementation will give better results than bilinear TPT (which, I think, is equivalent to bilinear state space discretization, because they are using the same state variables), but your "bold claim" is indeed quite far-fetched at this point, since to be of practical relevance, you have to provide some numbers about computational cost/sample as well and this is where I have strong doubts about your approach. For a modern soft-synth, I expect audio-rate cutoff modulation which implies updating your exp(AT) every sample. The same is necessary if you want to introduce nonlinearities (using mystrans approach). Also, comparing a SIMD implementation to a scalar TPT algo is also not entirely fair, since although a single TPT filter is not easily "SIMDable", in a synth I can use SIMD to compute 4 filters (4 voices) in parallel. Don't get me wrong, I'd be happy to be proven wrong, but at this point, I'm fairly sceptical your approach gives more "bang for the buck" than the TPT-BLT approach.
If not for anything else, your post did make me read material about linear dynamic systems, state space represantion etc., a topic I didn't bother with too much until now but which is certainly worth a read, so thanks for that!
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
Ok, I withdraw my bold claim. I was surprised how bad the performance of Will Pirke's implementation was - it didn't actually seem any better than the Huovilainen one. As you say, it's now obvious that it's a wrong implementation.
Now I'll have to more deeply understand the TPT approach so that I can implement it correctly. This will no doubt take a few days.
I'm still fairly optimistic about total bang for the buck, but now it's clear there's more of a tradeoff.
Now I'll have to more deeply understand the TPT approach so that I can implement it correctly. This will no doubt take a few days.
I'm still fairly optimistic about total bang for the buck, but now it's clear there's more of a tradeoff.
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
I redid the TPT plots based on mystran's implementation in the "cheap non-linear zero delay filters" thread, and they're looking much more reasonable. Will Pirke should revise or withdraw his application note, as it's seriously misleading (although of course I take responsibility for jumping the gun - I should have realized that the response was identical to the analog prototype save for bilinear frequency warping).
http://levien.com/ladder/graphs2.pdf
So I stand by my claim that the matrix exponential version is more accurate, although not extremely dramatically so. The TPT filters are very good, certainly much better than anything derived from the Stilson-Smith lineage with a unit delay.
Regarding performance, yes, you're in a slightly different world when you're modulating the filter parameters at audio rate. By my count, one TPT is a tangent, two divides, and 28 multiplies. My exp(A) is pretty good but doing one per sample probably won't keep up with TPT.
So my revised claims are:
* More accurate than TPT for Moog ladder
* Likely faster than TPT when updating parameters at less than audio rate
* Easily SIMD'able
mystran's approach to nonlinearity looks very interesting indeed. I think it's worthwhile to compare it against a more direct approach to solving the differential equations.
http://levien.com/ladder/graphs2.pdf
So I stand by my claim that the matrix exponential version is more accurate, although not extremely dramatically so. The TPT filters are very good, certainly much better than anything derived from the Stilson-Smith lineage with a unit delay.
Regarding performance, yes, you're in a slightly different world when you're modulating the filter parameters at audio rate. By my count, one TPT is a tangent, two divides, and 28 multiplies. My exp(A) is pretty good but doing one per sample probably won't keep up with TPT.
So my revised claims are:
* More accurate than TPT for Moog ladder
* Likely faster than TPT when updating parameters at less than audio rate
* Easily SIMD'able
mystran's approach to nonlinearity looks very interesting indeed. I think it's worthwhile to compare it against a more direct approach to solving the differential equations.
-
- KVRAF
- 8491 posts since 12 Feb, 2006 from Helsinki, Finland
For LTI case you can go further and do it like this: http://www.lce.hut.fi/~ssarkka/pub/eq-article.pdfZ1202 wrote:The solution is not exact, because of naive resampling involved. It's just a different set of compromises. For that reason, it would be nice to compare the amplitude (and phase) response graphs of analog, BLT and squared-matrix filters.mdsp wrote:Of course, this is the main problem. Matrix computations can dominate the CPU cost in the worst-case.mystran wrote:Doesn't the exponentiation get a bit costly (especially for bigger systems) if you need audio-rate updates?
However in the linear time-invariant case this approach shows that one can solve the continuouts differential equation system exactly (within numerical accuracy and input/output discretization hypothesis) instead of having to make compromises on the time or frequency response.
Regards,
{Z}
But inconvenient if the filter is non-linear (ie needs to be updated at least once per sample).
-
- KVRAF
- 8491 posts since 12 Feb, 2006 from Helsinki, Finland
Note that if you do TPT with LDU factorization (storing reciprocals of the diagonals) then the cost of solving the system is just two diagonal solves (with combined worst-case without sparsity being roughly the cost of a matrix-vector multiply). The factorization only needs to be updated when parameters change (which can be done at a control rate if you want). You could theoretically also calculate the full inverse, but that'll destroy any sparsity and has a higher elimination cost. Naive LDU leads to a few more divisions [one per dimensions, though you get back to 2 by pre-scaling in case of the currently discussed Moog model] during factorization, but it's hardly an issue if you're doing it at a control rate.raphx wrote: Regarding performance, yes, you're in a slightly different world when you're modulating the filter parameters at audio rate. By my count, one TPT is a tangent, two divides, and 28 multiplies. My exp(A) is pretty good but doing one per sample probably won't keep up with TPT.
Further if only some of the dimensions of the system are non-linear (say you have a single scalar non-linearity) then you can put those dimensions last and only update the factorization of the changing parts. So for a (sparse) 4x4 system with a single non-linearity (but control-rate parameter updates), you have the two (sparse) 4x4 triangular solves (and one component-wise vector multiply for the diagonal) plus factorization of a 1x1 non-linear system (and in fact you can use Newton-Raphson to solve just this scalar equation, without having to iterate the whole thing.. same for solving NxN system for N non-linear dimensions in a larger system).
So basically if you have a (M+N+K)x(M+N+K) system with N non-linearities and K time-varying coefficients, you only need to factorize the (N+K)x(N+K) system when the parameters change, and iterate the NxN system. Rest is just some triangular solves. That's what I personally like about the approach.
That said, the frequency-warping of trapezoidal is certainly annoying in several ways (with the cost of a tan() being the least of them, IMHO).
-
- KVRAF
- 8491 posts since 12 Feb, 2006 from Helsinki, Finland
Also, if one is willing to calculate (I+AT/2)(I-AT/2)^-1 then one can also repeatedly square that one, right?
-
- KVRist
- Topic Starter
- 46 posts since 20 Jun, 2013 from Berkeley, CA
A few themes here.
1. The (I + AT/2)/(I - AT/2)^-1 approach definitely works, but I strongly suspect that the matrix inversion is going to cost more than evaluating a few terms of a Taylor's series. I think for bigger systems it might be a win. As I said, the papers on matrix exponential suggest starting with a Padé approximant then repeated squaring, and that formula is the m=1, n=1 Padé approximant of exponential. Of course, as the polynomial degrees in the Padé go up, you're still only paying for the inversion once.
In any case, the best approach I've found so far is to do a short Taylor's series followed by squaring. Both the cost and the benefit of each such step are roughly equal, so doing an equal number of both is close to optimum.
2. If you want to modulate cutoff at audio rate, I think there's a technique that would work extremely well within the exponential framework: interpolation.
Briefly, exp(lerp(A, B, t)) ~ lerp(exp(A), exp(B), t), with an error of about (||A-B||)^2. So if you want to keep your norm down below 1e-6, that means you can have your cutoff control points spaced about 1e-3 apart (that's about 7Hz). So I think you can get the rate at which you actually need to do exponentials down quite a bit, and the overall speed extremely competitive with the TPT approach.
Of course, I'm sure you could do similar interpolation on the TPT parameters as well. But I think the matrix approach may have the speed edge yet, because of the parallelism of the matrix operations.
3. Yes, the Särkkä and Huovilainen technique describes both the matrix exponential technique for discretizing analog filters and also explains how to add a FIR that works in state space to curb aliasing of the frequency response. My intuition is that it's not needed for lowpass filters (unless you're shooting for insane levels of accuracy) but is for highpass. I'm also thinking of ways to make it a little faster - I'm thinking you could do actual upsampling (say 2x) using a standard scalar FIR, then use a very small one of those vector FIR blocks to get the signal into the state vector. But I haven't thought this all the way through.
I think the next stop is to really listen to how nonlinearity would work. I think the approach in my original paper would be effective and efficient, keeping the filter parameters themselves. But that said, your transconductance solution is very smart, and it might well be hard to match it.
1. The (I + AT/2)/(I - AT/2)^-1 approach definitely works, but I strongly suspect that the matrix inversion is going to cost more than evaluating a few terms of a Taylor's series. I think for bigger systems it might be a win. As I said, the papers on matrix exponential suggest starting with a Padé approximant then repeated squaring, and that formula is the m=1, n=1 Padé approximant of exponential. Of course, as the polynomial degrees in the Padé go up, you're still only paying for the inversion once.
In any case, the best approach I've found so far is to do a short Taylor's series followed by squaring. Both the cost and the benefit of each such step are roughly equal, so doing an equal number of both is close to optimum.
2. If you want to modulate cutoff at audio rate, I think there's a technique that would work extremely well within the exponential framework: interpolation.
Briefly, exp(lerp(A, B, t)) ~ lerp(exp(A), exp(B), t), with an error of about (||A-B||)^2. So if you want to keep your norm down below 1e-6, that means you can have your cutoff control points spaced about 1e-3 apart (that's about 7Hz). So I think you can get the rate at which you actually need to do exponentials down quite a bit, and the overall speed extremely competitive with the TPT approach.
Of course, I'm sure you could do similar interpolation on the TPT parameters as well. But I think the matrix approach may have the speed edge yet, because of the parallelism of the matrix operations.
3. Yes, the Särkkä and Huovilainen technique describes both the matrix exponential technique for discretizing analog filters and also explains how to add a FIR that works in state space to curb aliasing of the frequency response. My intuition is that it's not needed for lowpass filters (unless you're shooting for insane levels of accuracy) but is for highpass. I'm also thinking of ways to make it a little faster - I'm thinking you could do actual upsampling (say 2x) using a standard scalar FIR, then use a very small one of those vector FIR blocks to get the signal into the state vector. But I haven't thought this all the way through.
I think the next stop is to really listen to how nonlinearity would work. I think the approach in my original paper would be effective and efficient, keeping the filter parameters themselves. But that said, your transconductance solution is very smart, and it might well be hard to match it.