I agree with your statement and especially your concerns. On the other hand, I find myself, as an individual human being, wishing I had (more) control over the status of music today. So, I also want to dictate to others how they make music and what significance the experience of music should have for them. I'm shocked at how similar I am to the system I'm criticizing.ROTMetro wrote: Fri Aug 08, 2025 2:23 amAnd now we have new tribes that are happy to be fed music from a corporate trained, corporate approved machine with a corporate overwatch governor daemon judging every prompt given, all output released to make sure it meets corporate ethos. Yummmm.
Are AI-Generated Songs Ethical? Let's Talk About It.
-

- KVRAF
- 2038 posts since 8 Feb, 2013 from Switzerland
-
- KVRAF
- 16724 posts since 13 Oct, 2009
AI is glazing you. You need to push back. Scholars don't expect to make a living from textbooks. That ship has long sailed. Nor are they going to stop writing in their field because AI can help students, that is academic suicide. Now, if you want to start asking questions about the predatory publishing industry or the insular and bloated system of academia, then we can have a conversation. With respect to this conversation, however:ROTMetro wrote: Fri Aug 08, 2025 2:39 am AIs take on my position:
The Problem with AI and the Erosion of Copyright
I write history textbooks. They take years to research, write, and fact-check. But AI systems can now "train" on my book—absorb its structure, its clarity, its factual labor—without compensating me.
First, AI does not regurgitate anyone's textbook. This is a lay misunderstanding. Can it create similar looking documents when prompted carefully, absolutely, but that is not an indictment in and of itself. You can see this effect most easily on much smaller models run locally. It's harder to achieve on the latest large LLMs. That it occasionally creates something very similar is no different than telling a cover band to play a Beatles song and to keep adjusting your instructions until it sounds exactly like the Beatles.
Second, students stopped buying textbooks years ago, long before AI came along. In fact, there is a significant movement towards OER (Open Educational Resources) because there are huge advantages to this, particularly in terms of of access. OpenStax has been around since 2012 producing open textbooks with no catch.
Third, copyright has long been increasingly more exclusionary to benefit large corporations. Copyright is a temporary monopoly on content to benefit society, not a forever grant of profit to the creator. There are huge problems with current copyright laws, to include the absence of a de minimis defense for audio sampling. AI is forcing us to look at this again and potentially adapt our laws for a new century.
Fourth, and this is the big takeaway. AI is the new printing press. Like the printing press it will challenge the status quo, but it has the potential to significantly benefit society. Yes, there will be growing pains but we're already seeing reasonable decisions. While I don't agree completely, the choice to not grant copyright protection to AI generated works is a good start.
OpenAI wants you to keep chatting and to see them as valuable. They want your $20/Month. So, they are going to keep pleasing you, you are feeling the alignment layers, not the truth. To use AI effectively about subjects in which you are uneducated you have to push back, give more context, cross reference, and often, simply tell it to stop glazing you.
-
- KVRAF
- 3333 posts since 19 Mar, 2008 from germany
But that's what it does: The AI regurgitates exactly what it's fed asghettosynth wrote: Fri Aug 08, 2025 3:20 am
...
First, AI does not regurgitate anyone's textbook. This is a lay misunderstanding. Can it create similar looking documents when prompted carefully, absolutely, but that is not an indictment in and of itself. You can see this effect most easily on much smaller models run locally. It's harder to achieve on the latest large LLMs. That it occasionally creates something very similar is no different than telling a cover band to play a Beatles song and to keep adjusting your instructions until it sounds exactly like the Beatles.
...
"learning material." It doesn't repeat it exactly 1:1, but it
paraphrases the content. And it does so quite precisely.
In abstract terms, an AI is a neural network that is fed an input
vector and constructs an output from it, which is then compared
with a target vector. The result can be thought of as "rumination."
The most common counterargument I hear is, "But that's exactly
what we humans do." That's your argument about the Beatles
cover band.
And that's where I see a huge difference: There is indeed a
difference between a real person reproducing something they
perceived long ago and modified, emotionally adapted, and
changed many times through their subconscious and emotions.
Or a machine — with its neural algorithm and almost infinite memory
— reproducing it in a slightly modulated way.
The difference is so immense because it is also quantitative – and
will revolutionize not only music composition, but all areas of human
activity. As one of the Open AI founders once said: "The emergence
of AI is worse than the atom bomb." In the long run, AI will decouple
humans from creativity – and eventually even take over all
administration in the world.
free mp3s + info: andy-enroe.de songs + weird stuff: enroe.de
-
- KVRAF
- 16724 posts since 13 Oct, 2009
That’s not correct. Large language models do not store source material and then reword it. They construct a high-dimensional statistical model of token relationships from the training data, and generation is the process of sampling from that probability space. If the output resembles a paraphrase, that is incidental and comes from strong correlations in the data influencing prediction, not from retrieving and restating the original content. Humans do something similar without thinking about it, which is why it’s common for people to gradually adopt the language cues, slang, and speech patterns of those they spend the most time with.enroe wrote: Fri Aug 08, 2025 6:00 amBut that's what it does: The AI regurgitates exactly what it's fed asghettosynth wrote: Fri Aug 08, 2025 3:20 am
...
First, AI does not regurgitate anyone's textbook. This is a lay misunderstanding. Can it create similar looking documents when prompted carefully, absolutely, but that is not an indictment in and of itself. You can see this effect most easily on much smaller models run locally. It's harder to achieve on the latest large LLMs. That it occasionally creates something very similar is no different than telling a cover band to play a Beatles song and to keep adjusting your instructions until it sounds exactly like the Beatles.
...
"learning material." It doesn't repeat it exactly 1:1, but it
paraphrases the content. And it does so quite precisely.
The same is true for audio models, only it is even more abstract because the tokens represent feature descriptions of the audio rather than words, and the model predicts sequences of those features based on statistical relationships rather than recalling any actual recordings.
No, that's not my argument for the Beatles cover band. I wasn't describing how we would do that, I was describing how you manipulate a large language model to get the outcome you want to make the false claims that are being expressed here.The most common counterargument I hear is, "But that's exactly
what we humans do." That's your argument about the Beatles
cover band.
I snipped the rest because it was based on a fundamental misunderstanding.
The comparison to humans is that, like AI, we learn to chunk information in patterns and use those learned patterns to create new material. This is, in effect, a sample of our own "vector space" of experiences, in a very loose sense, where each new creation is assembled from the structural relationships between the patterns we have internalized.
The fundamental difference is that we lack the computational resources to process very large amounts of data at once. Our cognitive strength is constrained by a relatively small short-term memory, often described as holding about seven items at a time, plus or minus two, re: George Miller’s classic work. This limitation forces us to rely on compression, abstraction, and selective attention rather than exhaustive pattern matching across massive datasets.
Hence, we can work with fewer samples and apply our greater cognitive depth, but an AI model with its relatively shallow cognition leans on massive computational resources and huge amounts of data. We have already accepted this kind of trade-off in other areas; think of calculators, where we give up doing the work ourselves in exchange for speed and scale in arithmetic.
This is not intelligence, but the question of whether it counts as creativity is less clear. Creativity is often little more than iteration and curation, and that is essentially what language models do.
-

- KVRAF
- 1934 posts since 18 May, 2021
When the data is corrupt in the Desert of the Real, Beyond the Last Thought, where intuition reigns, is the solace that will embolden and strengthen the soul, giving hope once more to this age of failing technique. eassae.com
-
- KVRAF
- 5444 posts since 15 Feb, 2020
There is evidence of some approximate memorisation within latent diffusion models (for images).
https://arstechnica.com/information-tec ... difficult/
https://arstechnica.com/information-tec ... difficult/
I lost my heart in Cap de Creus
-
- KVRAF
- 16724 posts since 13 Oct, 2009
She's far too gleeful in getting you to click on her stuff. The class action determination is already being challenged.
https://arstechnica.com/tech-policy/202 ... -certifiedLast week, Anthropic petitioned to appeal the class certification, urging the court to weigh questions that the district court judge, William Alsup, seemingly did not. Alsup allegedly failed to conduct a "rigorous analysis" of the potential class and instead based his judgment on his "50 years" of experience, Anthropic said.
However, let's be clear here. The argument that one shouldn't pirate works is sound. That has been viewed as copyright infringement. Where there is a problem with the KVR interpretation is that training is necessarily copyright infringement. That is, we are talking about two separate things here. AFAIK, Anthropic is being sued for mass downloading, not training.
At the moment, as far as I understand and I am not a lawyer, is that this has had at least one ruling stating that it isn't. That's not decisive as people often think that it is, but it is a legal statement that AI is transformative. What I think that KVR, and others, often fail to understand is that the U.S. courts have long viewed transformative technologies as fair use.
https://www.bbc.com/news/articles/c77vr00enzyoA US judge has ruled that using books to train artificial intelligence (AI) software is not a violation of US copyright law.
The decision came out of a lawsuit brought last year against AI firm Anthropic by three authors, including best-selling mystery thriller writer Andrea Bartz, who accused it of stealing her work to train its Claude AI model and build a multi-billion dollar business.
In his ruling, Judge William Alsup said Anthropic's use of the authors' books was "exceedingly transformative" and therefore allowed under US law.
The idea here is that the copying is not being done to compete with the book, but, to use the material in a transformative manner. There are multiple precedents for this, but, the one probably most understandable/relatable here is the ruling that allowed individuals to video record in order to time shift.
Moreover, that these transformative actions can occasionally be abused, that is, someone may record a show to present it to a group, does not invalidate the overall transformative nature of the technology.
In other words, this:
Is likely of no moment. In these cases researchers are using adversarial prompts to obtain extremely similar or identical copies in a tiny minority of cases. There are specific facts in this research that help lead to this, for one, the cases involve duplicate entries in the training data. I'm quite sure that this will most likely just lead to refined data filtering on intake to avoid this self-imposed bias in the data.revvy wrote: Fri Aug 08, 2025 1:12 pm There is evidence of some approximate memorisation within latent diffusion models (for images).
https://arstechnica.com/information-tec ... difficult/
There is a long standing misunderstanding that one's creative output is protected by copyright no matter what and that when someone else uses it that it is definitionally immoral. Make up whatever stories you need to tell yourself, but the courts don't agree. A good example is schematics. I have to laugh at Eric Barbor's comments on the schematics that he published with the basic idea of Metasonix VCOs. The claim that if you used them in a competing product that he would sue. You can sue for anything, winning is a different matter.
So, as we understand it now, training on data is considered by one ruling as fair use. However, who knows what further rulings, deals, or agreements will do to shift this landscape. It's often the case in copyright law that one form of media has different protections than others. For example, there is a de minimis defense for text, but not for audio sampling, however, several court rulings have failed to uphold the bright line rule laid out by the supreme court. So it's not simple, it's not cut and dry, and it's probably not going to go the way that KVR wants it to. AI music is most likely here to stay.
-
- KVRAF
- 1934 posts since 18 May, 2021
This long, but a worthwhile watch.
Last edited by eassae on Sun Aug 10, 2025 4:44 pm, edited 1 time in total.
When the data is corrupt in the Desert of the Real, Beyond the Last Thought, where intuition reigns, is the solace that will embolden and strengthen the soul, giving hope once more to this age of failing technique. eassae.com
-
- KVRAF
- 1934 posts since 18 May, 2021
When the data is corrupt in the Desert of the Real, Beyond the Last Thought, where intuition reigns, is the solace that will embolden and strengthen the soul, giving hope once more to this age of failing technique. eassae.com
-
- KVRist
- 58 posts since 14 Dec, 2010
Suno was more impressive than I expected. I imported a song I'd composed and written a basic arrangement for. The remix function did some very cool things to it.
As an arrangement/remix tool I believe Suno to be very useful, especially for the lone bedroom producer. But that is my first impression. With time I suspect we learn to spot artificial material in music, just like we spot special effects in movies. And those things get old eventually and look bad.
As an arrangement/remix tool I believe Suno to be very useful, especially for the lone bedroom producer. But that is my first impression. With time I suspect we learn to spot artificial material in music, just like we spot special effects in movies. And those things get old eventually and look bad.
-
- KVRAF
- 3333 posts since 19 Mar, 2008 from germany
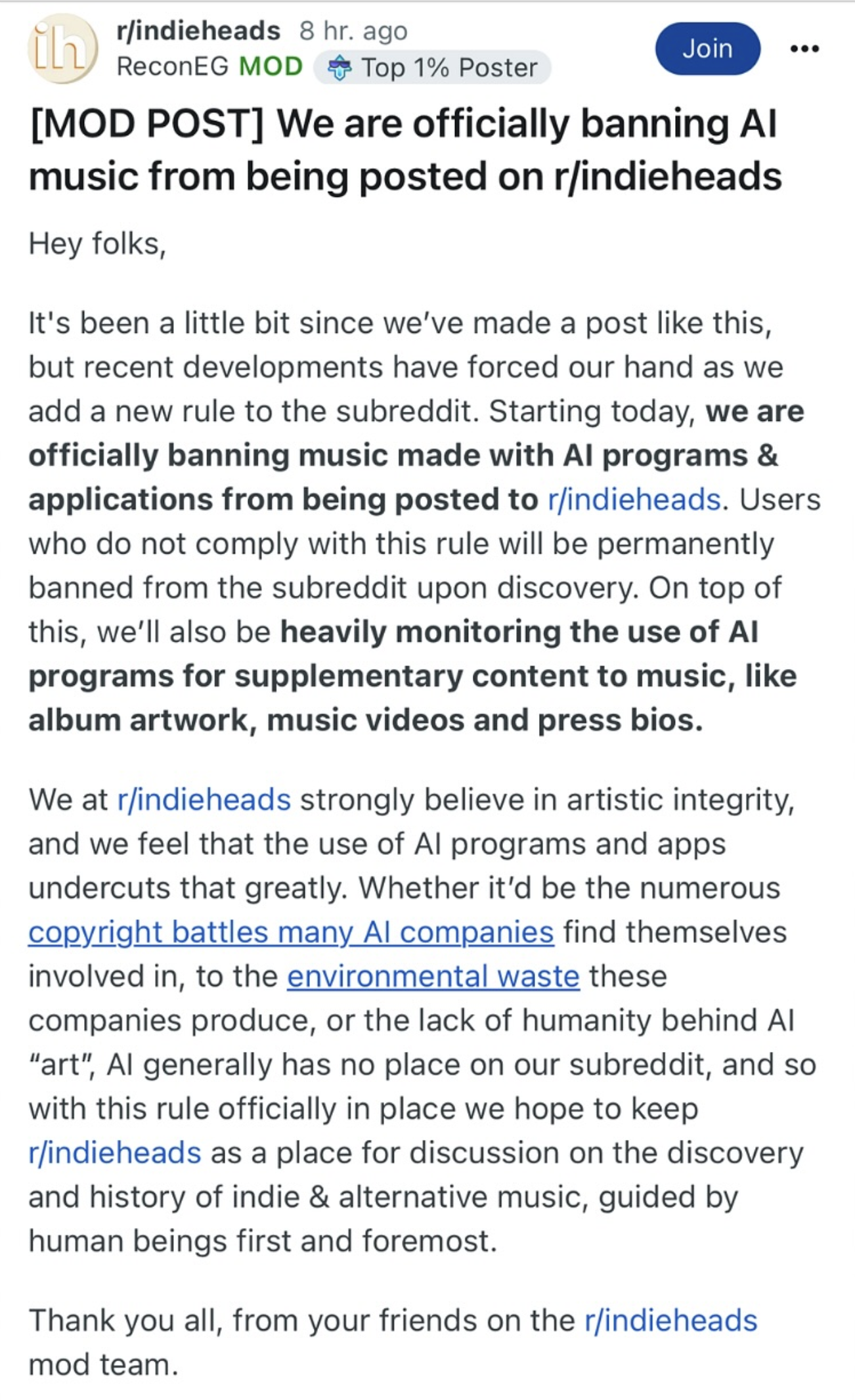
KVR should also adopt this rule. The moderators of r/indieheadseassae wrote: Sun Aug 10, 2025 12:58 am From reddit's largest music subreddit: https://www.reddit.com/r/indieheads/com ... usic_from/
have pretty clear articulated the reason for this.
AI-generated music no longer has anything to do with humanr/indieheads wrote: the lack of humanity behind AI "art"
composition, with human emotions, with the art and expression of
a human individual. AI-generated music is a purely computationally
assembled audio construct—humanity and individual expression
are completely absent here.
Instead, AI bots could operate their own platform. AI bots could then
listen to, consume, and rate AI-generated music, completely
independently of us humans.
free mp3s + info: andy-enroe.de songs + weird stuff: enroe.de
-
- KVRAF
- 1934 posts since 18 May, 2021
I would be happy if it did.
When the data is corrupt in the Desert of the Real, Beyond the Last Thought, where intuition reigns, is the solace that will embolden and strengthen the soul, giving hope once more to this age of failing technique. eassae.com
-

- KVRAF
- 1787 posts since 22 Feb, 2014
OpenAI reportedly developing new generative music tool
https://techcrunch.com/2025/10/25/opena ... usic-tool/
https://techcrunch.com/2025/10/25/opena ... usic-tool/
You do not have the required permissions to view the files attached to this post.
-

- KVRAF
- 2673 posts since 18 Mar, 2006 from The Void
Do humans prevent themselves from experiencing any other work whatsoever before releasing work ?Ah_Dziz wrote: Sun Oct 26, 2025 7:59 pm I'd believe they were ethical to be released original work if one could train them without anybody else's original work to train them.