19 KVR members have added AudioTexture to 10 MyKVR groups 23 times.
Download KVR Studio Manager (FREE)
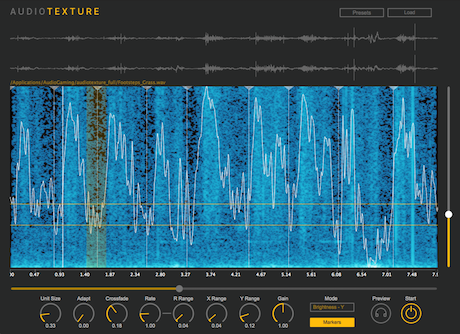
AudioTexture is based on concatenative synthesis which analyzes automatically the sound signal and decomposes it into adaptively defined units (not equal in size, so not the usual granular synthesis) for resynthesis. It is equipped with semantic descriptors for intuitive control to generate many variations from a given sound sample. The main features are:
AudioTexture comes with 3 descriptor controls in additional to the position control. This is convenient to create various unit sequences based on perceptually meaningful descriptors:
Reviewed By petekellock [all]
February 10th, 2021
Version reviewed: v1.3.1 on Mac
As far as I can tell, this doesn't do some of what it's supposed to. It plays segments of the audio file and the "Position-X" mode seems to work OK, but I can't see any sign that it does anything based on analysis of the signal (ie concatenative synthesis) as it claims. Using multiple different audio files I tried changing the range in Energy, Noisiness and Brightness modes and I can't see or hear any correlation between the level of these parameters and the selection of segments. This is the functionality I bought it for, and as far as I can tell it's simply not doing it; it seems just to select segments pretty much at random regardless of how you set the range. The manual is thin with very little explanation, so it's hard to tell what it's supposed to do, but I'm just not seeing evidence of the smart analysis-based functionality I expected.
Then there's the "R Range" control which the manual says is "Pitch shift randomization around the Rate factor". It doesn't seem to work at all for me - after many tests on different material with different settings, I never got any random variation in the pitch.
And it crashes a fair bit (I'm using the MacOS version on Mojave).
I hope Le Sound will release an upgrade which addresses all this. The concept is a great one: concatenative synthesis is a powerful technique which I've seen some great demos of.

Please log in to join the discussion
Submit: News, Plugins, Hosts & Apps | Advertise @ KVR | Developer Account | About KVR / Contact Us | Privacy Statement | Sell @ KVR | KVR Marketplace Terms & Conditions
© KVR Audio, Inc. 2000-2026
