

GPU Audio has been making waves as of late with their new technology allowing for the exciting potential of unlocking your computer's GPU for processing audio. KVR spoke with Sasha Talashov to discuss the possibilities and technicalities relating to GPU Audio processing and the future of the company.
Sasha is the CEO and co-founder of GPU Audio; managing the processes, partnerships, and people of GPU Audio as well as leading engineering, commercial, technological, and marketing aspects. As well as running the company, he also does significant R&D work, investigating the ways their tech can be implemented on new platforms such as M-Silicon GPUs and integrated via APIs such as Audio Units.
We've seen companies start to shift focus away from proprietary DSP platforms due to the sheer power of modern processors. However, there are presumably benefits to going down the GPU route as opposed to CPUs due to their superior ability to do parallel processing and computational work. Could you fill us in on some of the other reasons for this decision and additional benefits that offloading processing to a GPU may afford the end user?
The first thing to say is that using a GPU for audio processing is way more than a floating CPU. We started with traditional DSP algorithms and traditional plugins, to get our DSP models implemented and show the world that we can run audio processing on GPUs at low latencies and at scale - for desktops and laptops. Before this, graphics cards had spent years being idle - they did almost nothing except processing video, high end gaming, and post production. It's just great to have your GPU power unlocked for audio finally, because it's likely that most peoples' machines have more than just a CPU - it's a great opportunity to unlock the system's full potential.
The second point is that CPUs are occupied with many processes already and there is a huge variety of hardware systems for users today, for example the new MacBook M1/M2 systems. Regardless of the fact that one silicon chip is both powerful and highly efficient - it can run simple plugins, and lots of them - but it can't run things like live machine learning without encountering significant issues. GPUs enable this machine learning to happen, so that's one of the great use cases we have for desktop and laptop grade systems.
We believe that we need to enhance the power that can be accessed for audio processing with GPU, even for laptops. It's just really impressive that we now have a laptop for $900 which can do things beyond what traditional desktops could do. That's why it is worth unlocking and activating your GPUs for accelerated audio workflows on both systems. This is not just offloading or giving you superior performance on portable systems, it's also about unlocking or providing the very best standard for creating the next generation of tools and software.
So GPU processing is useful for production, and we imagine for live recording and performances too. Mixing engineers could have access to machine learning stuff, which is really exciting in terms of new possibilities it brings to the table.
What about other resource intensive applications such as spatial audio?
For spatial audio processing, you may be working with tens or even hundreds of audio tracks - but every track is processing multiple channels, typically from 8 to 32. Because of the huge amount of channels and dependencies that you usually present as some kind of matrix, you need to multiply the required processing power significantly. Spatial Audio is a really good fit for single-instruction-multiple-data devices like GPUs - it's a very natural platform to create plugins that can provide you a seamless experience when you mix and process audio, allowing you to work at very low latencies. We've spoken to people with the latest Macs and they are encountering CPU limits with Spatial Audio.
In terms of other resource intensive technology - you can look at what's going on with 3D and 2D graphics and machine learning algorithms; most of them work on GPUs, utilising them as a hardware platform. If the models need to be refined, we can train the models quickly. It's the same for audio - if you want to process some neural network models to some audio buffers, you have to use GPUs. Adaptive tools like noise removal, tone transfers, deep AI effects are some examples of those next generation machine learning techniques we can design and execute using GPU power.
You've recently released a beta suite of plugins as well as announcing a preliminary SDK for 3rd party developers. Do you have plans to expand on these in house plugins? How has the response been from the developer community with regards to the SDK?
 Some of them we will expand on, yes. We are not going to reveal all of our plans for the plugins we're creating but a beta-suite of plugins which will feature 10-15 classic audio plugin effects like compression, limiting, exciter, distortion, delay, and more. These will be released in bundles - the first one being the modulation bundle, of a chorus, a phaser and a flanger, which we released in October this year.
Some of them we will expand on, yes. We are not going to reveal all of our plans for the plugins we're creating but a beta-suite of plugins which will feature 10-15 classic audio plugin effects like compression, limiting, exciter, distortion, delay, and more. These will be released in bundles - the first one being the modulation bundle, of a chorus, a phaser and a flanger, which we released in October this year.
We also plan to roll out the technology to third party developers, and have a partnership with Mach1 to produce a Spatial Audio plugin. We have already signed 6 NDAs for partner product developments and we have many more arrangements with potential partners in discussion.
Later this year, we'll release an SDK. We just ran our first workshops at NVIDIAs Deep Learning Institute and it was an extremely positive experience - we had a fully occupied session, with 60 out of 60 spots and a full waiting list for the 2 hour workshop. We had people from Native Instruments as well as people from the other industries, such as Volvo - because even the automotive industries are extremely interested in the technology. Bang and Oulefsen are also keen on using embedded GPUs, so we have huge attention from developers.
There is an SDK page online, where you can sign up for it as soon as it's released. We're hoping third parties will be inspired to use it, and we're determined to make it simple for them to develop for. More on that later.
Will we eventually see fully featured DAW benefitting from GPU cards? Is it going to be possible to have GPU Audio processing (for example) Ableton Live?
So far, the focus has been on showcasing our advancements in GPU processing. We will eventually see a fully featured DAW - but we can't provide more detail on that right now. What I can say is that this will not be a standard DAW, or it will not be a DAW in a standard sense.
With regard to Ableton and the other DAWs, I guess not - we'll probably try to provide some integration between our DAW and others but our strategy is essentially to release plugins for all of the DAWs through the interfaces such as VST, Audio Unit, AAX and hopefully CLAP.
We want to make those plugins and our partner plugins part of our own DAW. We want to make sure that we don't just create another island to work on - meaning that there will be GPU powered plugins; our plugins and partner plugins developed for the DAWs. The other DAWs architecture is extremely outdated - we see that we can make things, implement and achieve them very differently, resulting in users having more time to invest in actually creating their stuff.
Recently, there have been numerous advancements in the audio industry exploring the use of AI in audio production. Several developers such as Steinberg, with their DrumGAN Neural Net in Backbone, as well as Sonible and Izotope's various product lines, incorporate machine learning into their products. Do you foresee GPU Audio playing a role in furthering this technology?
We see it as not just a role GPU Audio has in furthering this technology - it's a key component to the advancement and implementation of it. I don't see any other software companies which can run machine learning algorithms in real time without encountering high CPU loads - especially running deep learning or high quality neural network powered models in real time.
So far, it's extremely hard to get high quality models working well at low latencies. There has been some good stuff done by many pro audio software companies, but it's different for us because we know how NVIDIA achieved it for their Maxine SDK. iZotope and similarly respected companies cannot do such high quality models using CPUs only, compared with what NVIDIA did on their GPUs. We understand how many layers GPUs have to process in order to make these models work at low latency. This is huge, and CPUs simply can't run them with real time latencies. That's the reason we believe GPUs have the power.
Having said that, we definitely don't have our own products fully finished and published yet - we don't have such features as AI processing as a part of the SDK yet, because machine learning engineering is very different. In order to support machine learning and develop machine learning power tools, we will have to provide both front end support and back end support because machine learning engineers usually work with Python scripts - they assemble prototypes of models, then they train those prototypes using scripts in Python, so they have a specific development workflow and we can't change that.
We envision that 3rd parties will be able to actually build prototypes using our front end, just in the same way as usual plugins without investing too much of their time in it. This is one very, very significant thing we have to provide and we fully understand that.
The second thing is that we have to provide the backend of the technology, so the scripts and prototypes that are built in the pilot environment can actually be compiled and assembled with our back end technology. This way it will run within our scheduling environment at low latencies at scale, and together with any other machine learning on machine learning, but still GPU powered solutions.
So this is the reason we didn't release everything there yet, because we have to provide all of those layers. Aside from those features, we're confident we can make machine learning and neural networks powered by GPU software, and no one else can actually make it for GPUs, and actually, there is no other way to do it. We understand the challenges, especially in development, and that the challenges the next generation standard has to take on and resolve in order to push the entire industry forward for everyone.
A reduction of latency would presumably be seen in offloading tasks to the GPU. Hypothetically, how low could you go when processing audio? Would we potentially see near latency free processing at the audio inputs in DAWs whilst recording?
The lowest latency we have in the entire system for the entire data flow, including some filters running at scale is 30 microseconds, but we usually say 150 microseconds when we need to complete the entire process such as process a chorus or something like that.
Using GPUs we have plenty (thousands) of cores and we are reducing the latencies of our product assembly down to 10s of microseconds. Using a GPU for processing audio means there will almost never be issues with the latency people experience right now with standard setups. The problem, I would say, would be potentially seeing latency in the audio inputs in the DAW whilst recording - so then you might see it happening with our early access plugins and beta plugins bundle in these early stages.
Effects often run in many chains in parallel over a lot of tracks, with video, or multiple channels within one millisecond latency. I can't imagine that you need less than that. It could feasibly be less than that in broadcasting circumstances but for the most part, for almost everything in recording, you don't need to go lower than that. A human can barely notice any difference. Usually people work with three, five milliseconds, so we set our "golden rule" as fitting into one millisecond.
You've recently announced official partnerships with both AMD and NVIDIA, and now Apple too with support for Metal and M1 series processors on the horizon. Have there any major challenges in adapting your technology to different hardware and frameworks from these companies?
 Definitely. Well, DSP wise, we have three parts of the technology. One is the device side of the technology, which is the scheduler - which allows us to parallel process audio by prioritising tasks. This is an assembler language level implementation that we created specifically for NVIDIA, and we created it specifically for AMD too. We might possibly create something for the M Silicon GPUs as well, and for Intel, once they're on the market. Another part is host side implementation with driver API's and other processes relating to how you treat GPUs with workloads etc. The third part is DSP implementation of the algorithms written mostly for the device side and partially for the host side - all of that stuff is already unified as a GPU audio library.
Definitely. Well, DSP wise, we have three parts of the technology. One is the device side of the technology, which is the scheduler - which allows us to parallel process audio by prioritising tasks. This is an assembler language level implementation that we created specifically for NVIDIA, and we created it specifically for AMD too. We might possibly create something for the M Silicon GPUs as well, and for Intel, once they're on the market. Another part is host side implementation with driver API's and other processes relating to how you treat GPUs with workloads etc. The third part is DSP implementation of the algorithms written mostly for the device side and partially for the host side - all of that stuff is already unified as a GPU audio library.
There are some particular limitations for various platforms like low assembly level permutations of the scalar technology. But for third party developers when they want to code something like a product or display component, it will look absolutely similar. They will use the same API for any hardware platform. That's the whole point of utilising the GPU audio SDK and nothing else.
The second thing is that clearly AMD and NVIDIA GPUs on the device side are different - however, we adopted our first original implementation of NVIDIA technology to AMD through a variety of software Computer Science and Engineering tricks like HIP or building software for Linux then porting it to Windows.
It will look the same for Intel GPUs, but for Apple computers it's absolutely different. First of all because Apple ISA - Instruction Set Architecture or assembler for GPU, is a proprietary technology so it's closed - there are very few papers you can read and understand how it works. This is different to AMD and NVIDIA stuff, So we can't make a device side scheduler for M-Silicon GPUs like we did for their hardware. This means that M silicon implementation will be less efficient when compared with NVIDIA - if we can pair two abstract things together, it will be less efficient because we don't have access to some features that are very significant for us.
The hardware is different and it's different from a software model perspective and the science. It's first of all SOC. So it's the same system on chip, CPU and GPU of silicon share the same memory space and so from both software and hardware point of use Apple does a lot for third parties like us. This is not the same thing that we do internally for NVIDIA or AMD platforms, this is way different. And because of that, they have some hidden behaviours or uncommon common situations with unexpected behaviour, resulting in non typical situations. Shortly speaking, it's a huge pain in the neck to basically build anything for Apple.
But still, we've already built the Early Access product for Macs and there is some device side scheduling, but it's not that advanced yet. We have good performance for the M-1 Macs which have seven or eight GPU cores. So we squeezed the M silicon GPU power almost to its own theoretical maximum. So for us and for the others, it means that we know how to utilise M silicon GPUs in the same way we did for AMD and NVIDIA to provide accelerated audio computing solutions. It also means that there are many problems, but we are figuring them out, and we will provide the same API's for other developers to build stuff for Apple.
From a developer's perspective, are there considerations to be taken when pertaining to the different hardware, or does the GPU Audio Scheduler do all the heavy lifting in this regard?
No, nothing like that - no heavy lifting. This is the purpose of providing an SDK; we want to hide the details that ordinarily are taken care of by GPU code developers - we want to hide the multiple cores and thread management, we want to give you building blocks to build your own product.
You will not manage the GPU code like we do, however, it will also offer you the ability to write your own GPU code and manage threads and manage other aspects if you want to. If you want to build a very custom DSP block that you have missing in our SDK, then you would be able to use the SDK, provided that you are proficient in GPU development. If you want to bring, for example, machine learning using GPU audio stuff earlier than we provide, you would be able to do so.
And still you will benefit from the GPU because you would be able to load AMD and NVIDIA binaries to the same DAWs. You can load your and 3rd party plugins in a chain and run them with extremely low latency.
Furthermore, are there any benefits from owning a certain brand of GPU card with respect to GPU Audio, considering features like DLSS and FidelityFX are specific to NVIDIA and AMD cards respectively?
 There are almost no differences here - the only difference is your cores, we usually work with the CUDA cores, like the horsepower of the GPUs, GPUs that are built specifically for machine learning stuff have less CUDA cores, they have more tensor cores, more machine learning specific cores, and they cost a pretty decent amount of money. So you have to avoid those GPUs in case you want high quality and not high gain a less price ratio,
There are almost no differences here - the only difference is your cores, we usually work with the CUDA cores, like the horsepower of the GPUs, GPUs that are built specifically for machine learning stuff have less CUDA cores, they have more tensor cores, more machine learning specific cores, and they cost a pretty decent amount of money. So you have to avoid those GPUs in case you want high quality and not high gain a less price ratio,
Please just buy consumer grade GPUs and please, don't go to the volatile market of desktop GPUs - you should always buy laptops (in our opinion). Laptops are perfect, yesterday I saw an RTX 3070 Ti gigabyte laptop with 4k OLED screen for $1,400.
How about the next generation of GPUs? In terms of what we're putting out? And for developers, are you going to support the next generation of GPUs as well?
We're already supporting them. There are some (even in NVIDIA devices) where there might be some problems. When you're compiling the CUDA code for consumer grade GPUs or for datacenter grade GPUs, there are some dependencies and you might encounter some issues with this. But as far as I know, for the RTX, there are no such hardware dependencies, and they provide a very nice layer for us. So we shouldn't do anything in order to support the new common devices.
In the modern times, around eight years ago, there were some issues - right now, there should not be any issue in the AMD environment. On the AMD side, they're still on their road of unifying hardware limitations, their hardware platforms, their hardware, specific tools, as well as software and middleware. So neither we nor AMD itself has such nice cross compatibility between the devices like NVIDIA has, unfortunately. Regarding the AMD devices, it's not that way. But the cool thing about that is that we have a direct partnership with AMD, as you guys know, and we will figure this out. In the event that there was anything happening there specifically it might take like a month at most to fix because AMD is very supportive, and we already know what can be wrong. And with new GPUs, so for NVIDIA, it should be no brainer.
We recently saw you speak about a new GPU Powered synth called MAJOR. What can you tell us about it?
Yes, we got a lot of attention for that. We announced it on the Pro Synth Network podcast and I can share some of the specs below. It's really exciting to develop something like this - we're more than aware that talking about the tech isn't enough for some people - so being able to reveal a synthesiser to the music community is really exciting.
Major's hybrid synth engine will provide you with the best of both worlds - 8 synthesiser oscillators and 8 sample based oscillators, with 8 independent layers and unique effects chains. You'll have envelopes and independent output routing with built-in editable plugin chains and insert slots for the library of other GPU Audio powered effects.
We'll have MPE supported and flexible automation for most parameters using MIDI controllers, internal modulators or host automation. There will also be up to 4x oversampling and up to 64-bit length for real-time or individual "bounce mode".
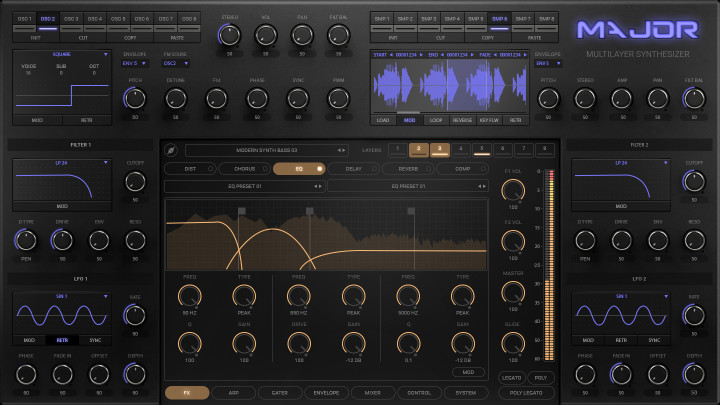 GPU Audio were able to provide some additional specs for each layer of their new upcoming GPU powered MAJOR Synth:
GPU Audio were able to provide some additional specs for each layer of their new upcoming GPU powered MAJOR Synth:
- 8 Synth-based & 8 sample-based oscillators.
- 16 voices per oscillator.
- OSC: 5 Alias-free waveforms including White Noise.
- OSC: Up to 128 voices per note.
- OSC: PWM for all waveforms.
- OSC: Detune, Stereo Spread, Panning and Filter Routing balance.
- OSC: FM modulation between oscillators.
- WaveOSC: Attack and Loop Wave players.
- WaveOSC: Stereo Spread, Panning and Filter Routing balance.
- Two 12,18, 24db/oct HP, LP and BP filters with resonance.
- 2 host-syncable LFO with 5 waveforms.
- 8 Envelopes with various curves.
- Internal Distortion, Chorus, EQ, Delay and Reverb with variable order.
- Up to 32-step Arpeggiator & Gater with swing.
- Two StepLFOs with up to 32 steps and swing.
- MultiControls for easy automation.
- 16 modulation lanes per each modulation panel.
- Legato, Polyphonic and Polyphonic Legato modes.
- Mass-Preset for Random Patching across all parameters, effects, layers, oscillators etc.

 Other Related News
Other Related News