38 KVR members have added Fauna to 10 MyKVR groups 46 times.
Download KVR Studio Manager (FREE)
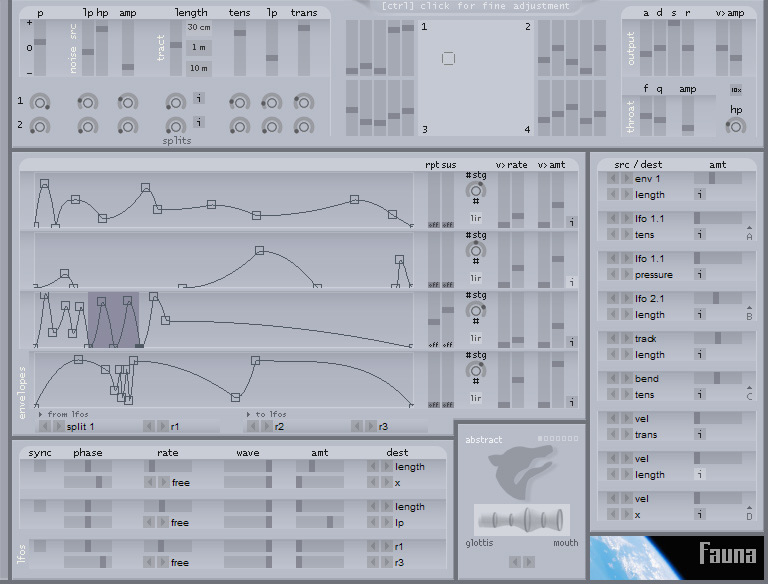
Fauna is a simple waveguide model of the vocal tract intended to provide a flexible platform for the synthesis of abstract and animal voices.
Waveguide synthesis is a physical modeling technique that makes use of delay lines to model the transmission of acoustic vibrations. A sample rate of 44.1kHz translates to a distance of less than 1cm under normal atmospheric conditions, so modern computers can achieve a degree of accuracy in acoustic modeling.
The delay bore is divided into five sections. Reflection coefficients control the transmission between segments, which effectively emulate the area of the tract at each position. Kelly and Lochbaum developed this speech synthesis technique in 1962.
Unlike conventional speech synthesizers, which use the tract to add formants to an oscillator, the fundamental pitch is determined by the overall form of the model.
The glottis acts like a reed, opening with air pressure from the lungs (determined by a pressure coefficient) and closing with air reflected back from the mouth. The position of the glottis is a result of these and other forces, such as tension and springiness of the muscle tissue.
Oscillation is produced by the balance of pressure waves in the tract and their effect on the glottis; as the size of the aperture changes, so do its properties of transmission and reflection.
Fauna VST uses four sets of five reflection coefficients to describe the shape of the vocal tract. Four 16-stage graphic envelopes and three dual-contour LFOs are applied to the tract coefficients. A bank of nine sends and two 'splits' route modulators to parameters as groups to assist in the emulation of organic forms.
The structure is not complex enough for speech, keeping in mind that the five coefficients describe the contour of the throat from the glottis and not from the back of the mouth. It may surprise you how many sounds it can create given the low waveguide count.
 $149.00OP-Xa V$149.00Synthx V$149.00Acid V
$149.00OP-Xa V$149.00Synthx V$149.00Acid V $209.00Diva
$209.00Diva
Please log in to join the discussion
Submit: News, Plugins, Hosts & Apps | Advertise @ KVR | Developer Account | About KVR / Contact Us | Privacy Statement | Sell @ KVR | KVR Marketplace Terms & Conditions
© KVR Audio, Inc. 2000-2026
